Next-Consensus-Architecture-Proposal
本文翻译于 https://github.com/hyperledger-archives/fabric/wiki/Next-Consensus-Architecture-Proposal
讨论和留言在这里
作者:Elli Androulaki, Christian Cachin, Angelo De Caro, Konstantinos Christidis, Chet Murthy, Binh Nguyen, Alessandro Sorniotti, and Marko Vukolić
译者:李康
本篇记录了区块链基础设施的架构,每一个区块链中的节点角色被划分为 peers 角色(维护状态和总账)和 consenters 角色(对包含在区块链状态里的交易最终顺序达成共识)。在大部分区块链架构中(包括2016年7月份版本的 Hyperledger fabric),这些角色是统一的(例如Hyperledger fabric 里的验证节点)。该架构同时引进了 endorsing peers ,一种特殊类型的 peers,来负责模拟执行和为交易背书(对应于 Hyperledger fabric 0.5 版本中执行和验证交易的行为)。
该架构与以前的设计( peers/consenters/endorsers 是一体的)相比有以下优势:
链上编码信任的灵活可用性(Chaincode trust flexibility)。该架构使对链上编码的信任假设从对共识的信任假设中分离开来。换一种方式来说,共识服务可以由一系列的节点(consenters)来提供,允许部分节点失败或者有恶意行为;而对于每一个链上编码 endorsers 可以是不同的。
可扩展性(Scalability)。 当负责特定的链上编码的 endorser 节点与 consenters 节点是统计上独立的时候,系统的扩展性相对于全部的功能被相同的节点实现这一方式要更好。尤其是,当不同的链上编码定义了不相交的 endorsers 集合的时候,这样就会产生链上编码之间的分离,可以允许并行地执行链上编码(endorsement)。还会将可能很耗时的链上编码的执行过程也与共识服务过程分离开来。
机密性(Confidentiality)。该架构使得对它所属的交易的内容、状态更新有具体机密性要求的链上编码的部署更加便利。
共识模块化(Consensus modularity)。该架构是模块化的,并且允许可插拨的共识实现。
目录
- 系统架构
- 交易背书(endorsement)的基本工作流程
- 背书策略
- 区块链数据结构
- 状态转移与检查点(checkpoint)
- 机密性
1. 系统架构
区块链是一个由许多相互交流的节点组成的分布式系统。区块链运行着称为链上编码的程序,持有状态和总账数据,执行交易。链上编码是关键性元素:交易是一系列在链上编码上唤醒的操作,并且只有链上编码能改变状态。交易必须被认可(背书),并且只有背书过的交易才能被提交来影响区块链上的状态。可能会存在一个或多个特殊的链上编码来管理函数、参数,这些被称为系统级链上编码。
1.1. 交易
交易有以下两种类型:
部署交易 (Deploy transactions) 创建新的链上编码,使用一个程序作为参数。当一个部署交易成功执行后,链上编码就被安装在了区块链上。
唤醒交易 (Invoke transactions) 在某个具体的链上编码中执行具体的操作。一个唤醒交易指向一个链上编码提供的函数。当该交易成功执行后,链上编码会执行相应的函数,该函数可能会修改相应的状态并且返回一个输出。
就像随后描述的那样,部署交易是唤醒交易中一种特殊的类型,因为部署交易会创建新的链上编码,对应于在某一个系统级链上编码的唤醒交易。
Remark: 该文献当前假设了一个交易要么创建新的链上编码,要么唤醒已经部署在区块链上的某个链上编码中的某个操作。该文献还没有描述:a)支持跨链上编码的交易,b)查询(read-only)交易的优化。
1.2. 状态
区块链状态。 区块链的状态 (world state) 有一个简单的结构,被建模为一个版本化的键值存储 (KVS),其中,键是名称,值是任意的数据。这些键值对条目被运行在区块链上的链上编码 (应用程序) 通过 put 和 get KVS 指令操作。状态被持久化的存储,并且对状态的更新操作会被日志记录。注意,版本化的 KVS 是作为一种状态模型适配的,一个具体的实现可以使用实际的 KVSs,但是亦可以是 RDBMS (关系型数据库管理系统) 或者其它的解决方案。
更加正式地,区块链状态 s 被建模为映射关系 K -> (V X N) 的一个元素:
K是键的集合V是值得集合N是一个无限有序的版本号集合。一对一映射函数next : N -> N,输入N的一个元素,返回下一个版本号。
V 和 N 都包含一个特殊的元素 ⊥,暗示 N 中最小的元素。初始的时候,所有的键都被映射到 (⊥, ⊥)。对于 s(k)=(v, ver),我们通过 s(k).value 来表示 v,s(k).version 来表示 ver。
KVS 操作建模为如下:
put(k, v),对于k ∈ K和v ∈ V,取出区块链状态s并且将它变为s',有s' = (v, next(s(k).version))并且对于所有的k' != k,s'(k') = s(k')。get(k)返回s(k)。
状态分割 (State partitioning)。 根据 KVS 中的键的名称,我们能识别出它们具体属于哪一个链上编码,在某种意义上来说,只有属于某个特定链上编码的交易才能改变属于它自己键的值。原则上,任何链上编码都可以读取属于其它链上编码的键的内容(有机密性要求的链上编码的状态不能被明文读取 - 第6章有提及)。对于跨链上编码交易(可以修改属于两个或更多链上编码的状态) 的支持将会在未来添加。
总账 (Ledger)。 区块链状态的演化被记录在 总账 中。总账是包含交易的区块形成的哈希链。总账中的交易是完全有序的。
区块链状态和总账会在第四章有更详细的描述。
1.3. 节点
节点是区块链中交流的实体,某种意义上来说,一个节点就是一个逻辑上的函数功能,大量不同类型的节点能运行在同一台物理服务器上。关键的是节点如何以可信域 (trust domains) 被组织,并且与控制它们的逻辑实体相关联。
有3种不同类型的节点:
客户端或者提交客户端 (Client or submitting-client):提交一个实际的唤醒交易请求。
对等体 (Peer):提交认可交易并且维护状态和总账的副本。peers 有以下两种特殊角色:a. submitting peer or submitter,b. endorsing peer or endorser。
共识服务节点 (Consensus-service-node or consenter):运行着实现了传输保证 (例如原子性的广播)的交流通信服务的节点,传输保证由运行共识算法来实现。
注意客户端和共识服务节点不维护总账和区块链状态,只有 peers 维护。
1.3.1. 客户端
客户端代表终端用户行为的实体。它必须与一个 peer 相连接才可以与区块链交流通信。客户端可以按照自己的选择连接 peer。客户端创建和唤醒交易。
1.3.2. Peer
Peers 与共识服务节点交流通信并且维护区块链状态和总账。如此一来,Peers 从共识服务节点处接收有序的状态更新操作,并且将它们应用到本地持有的状态中。
Peers 有以下两种角色组成。
Submitting peer。 一个 submitting peer 是 一个 peer 的一种特殊角色,它提供一个接口给客户端,如此,客户端便能连接上它来唤醒交易并且获取结果。Peer 与其它的区块链节点相联系来执行一个或多个客户端提交的交易请求。
Endorsing peer。 endorsing peer 的特殊函数功能相对于特定的链上编码发生,并且在一个交易提交之前为其背书。每一个链上编码都可能会具体一种 背书策略 (endorsement policy),该策略指向一个 endorsing peers 的集合。该策略定义了一个有效交易背书 (典型的是 endorsers 集合的签名) 发生的必要且有效的条件。就像第二章和第三章描述的那样。部署交易这种特殊的交易类型,它的背书策略被具体为系统级链上编码的背书策略。
为了强调既不是 Submitting peer 也不是 endorsing peer 的 peer,这种 peer 有时候会被认为是 committing peer。
1.3.3. 共识服务节点 (Consenters)
consenters 构成了共识服务,例如一种提供传输保证的交流通信 fabric。共识服务可以以不同的方式实现:从一个中心化的服务 (在开发环境和测试环境中使用 ) 到分布式的协议 (旨在解决异构网络和拜占庭错误节点的模型)。
Peers 是 consenters 的客户端,Consenters 提供一个共享的交流通信的管道给 peers,该管道提供包含交易的消息的广播服务。Peers 连接上这个管道,用来发送和接收消息。管道支持所有消息原子性的传输,也就是,消息的传输是一个完全有序的并且可靠的。换句话说,管道向所有连接它的 peers 输出相同的消息并且消息是相同逻辑顺序的。原子性的交流通信也被称为完全有序的广播 (total-order broadcast) 或者是分布式系统中的共识。通过管道传播的消息是要包括进区块链状态的候选交易。
分割 (共识管道) (Patitioning (consensus channels))。 与发布/订阅消息系统的主题(Topics) 相似,共识服务可以支持多管道。客户端连接到一个给定的管道上,然后发送消息和获取到达的消息。多管道可以被认为是隔离的 - 客户端不会意识到其它管道的存在,但是客户端可以连接多个管道。简单起见,在本篇文献的剩余部分,除非显示地提到,否则我们假设共识服务由单 channel/topic 组成。
共识服务程序接口 (Consensus service API)。 Peers 通过共识服务提供的程序接口连接到由共识服务提供的管道上。共识服务程序接口由两个基本的操作组成 (更为普遍是异步事件 - asynchronous events):
broadcast(blob):submitting peer 调用该接口广播任意的消息blob在管道上传播。在 BFT 上下文环境中,这也被称作为request(blob),发送请求给服务。deliver(seqno, prevhash, blob):共识服务调用该接口,传送带有具体的非负整数序列号 (seqno) 和最近刚传输的消息的哈希值 (prevhash) 的消息blob给 peers。换句话说,它是来自共识服务的一个输出事件。deliver()在一个发布/订阅的系统中被称为notify()或者在 BFT 系统中被称为commit()。注意共识服务客户端 (peers) 只能通过
broadcast()和deliver()事件来与共识服务产生交互。
共识属性。 共识服务 (或者是原子性广播的管道) 需提供以下的保证。它们回答以下问题:广播过的消息发生了什么?传送过的消息之间存在什么联系?
安全性 (一致性保证) (Safety (consistency guarantees) ): 只要 peers 足够长时间的连接到管道 (它们可以断开连接、宕机,但是会重新启动、重新连接),它们将会看到一个相同序列的 delivered
(seqno, prevhash, blob)消息。这意味着,输出 (deliver() 事件) 在所有的节点上以相同的顺序发生,并且序列号是相同的消息,其内容(prevhash, blob)也是相同的。注意这仅仅是逻辑上的顺序,在某一 peer 上发生的deliver(seqno, prevhash, blob)不需要跟在其它 peer 上发生的同一输出deliver(seqno, prevhash, blob)有任何真实时间上的联系。换句话说,给定一个seqno,没有两个正确的 peer 会接收到不同prevhash和blob。还有就是,没有blob会被传送,除非某个共识服务客户端 (peer) 实际上调用了broadcast(blob),并且,优选的是,每一个广播过的blob仅仅被传送一次。此外,
deliver()事件 包括前一个deliver()事件的加密哈希值 (prevhash)。当共识服务实现了原子性广播的保证后,prevhash是带有序列号为seqno-1的deliver()事件的加密哈希。这就建立了一条跨deliver()事件的哈希链,可以被用来帮助验证共识服务输出的完整性,会在第四章和第五章有详细讨论。在特殊的第一个deliver()事件里,prevhash有一个默认值。可用性 (传送保证) (Liveness (delivery guarantee) ):共识服务的可用性保证通过具体的共识服务实现来定义,依赖于网络和节点错误模型。
原则上来讲,如果 submitting peer 不会失败,共识服务应该保证每一个连接到共识服务的节点最终会收到每一笔提交的交易。
总体上来说,共识服务保证了下列特性:
一致性 (Agreement)。 对于发生在正确 peer 上的两个
deliver()事件:deliver(seqno, prevhash0, blob0)与deliver(seqno, prevhash1, blob1),有prevhash0==prevhash1和blob0==blob1;哈希链完整性 (Hashchain integrity)。 对于发生在正确 peer 上的两个
deliver()事件:deliver(seqno-1, prevhash0, blob0)与deliver(seqno, prevhash, blob),有prevhash = HASH(seqno-1, prevhash0, blob0)。不会跳过 (No skipping)。 如果共识服务在一个 peer p 上输出了
deliver(seqno, prevhash, blob),那么 p 已经接受过deliver(seqno-1, prevhash0, blob0)事件。不会创建 (No creation)。 发生在节点上的任何
deliver(seqno, prevhash, blob)事件一定是由某个节点 (可能是不同) 上的broadcast(blob)事件产生的。不会重复 (No duplication) (可选的,强烈需要的)。 对于任何两个事件
broadcast(blob)和broadcast(blob'),当两个事件deliver(seqno0, prevhash0, blob)和deliver(seqno1, prevhash1, blob')发生在正确的 peer 的时候,并且blob==blob',那么有seqno0==seqno1和prevhash0==prevhash1。 (译者:跨deliver()事件的哈希链中不会出现两个具有相同blob的事件)可用性 (Liveness)。 如果一个正确的 peer 唤醒了
broadcast(blob)事件,那么每一个正确的 peer 最终都会发行一个deliver(*, *, blob)事件,* 代表任意值。
2. 交易背书的基本流程
接下来我们将给出交易请求工作流程的大概轮廓。
Remark: 注意下列的协议没有假设交易是决定性的,例如,它允许非确定性的交易。
2.1. 客户端创建一笔交易,然后按照它的选择将交易发送给一个 submitting peer
为了唤醒一笔交易,客户端将下列消息发送给一个 submitting peer spID。
<SUBMIT, tx, retryFlag>:
tx=<clientID, chaincodeID, txPayload, clientSig>:clientID是 submitting client 的 ID,chaincodeID指向交易属于的 chaincode,txPayload是包含提交的交易内容的有效载荷,clientSig是客户端对tx其它部分的签名。
retryFlag是布尔变量,告诉 submitting peer 当交易失败的时候是否再次进行提交。
txPayload 的细节在唤醒交易和部署交易之间会有所不同,对于唤醒交易来说,txPayload 由一个字段组成
invocation = <operation, metadata>,operation意味着链上编码的函数操作和参数,metadata意味着与唤醒相关的属性。
对于部署交易,txPayload 由两个字段组成:
chainCode = <source, metadata>,source代表着链上编码的源代码,metadata代表着与链上编码和应用程序相关的属性。
policies包含于链上编码相关的策略,可以被所有的 peers 所访问,例如,背书策略
TODO: 决定是否显示包含客户端本地/逻辑时钟 (时间戳)。
2.2. submitting peer 准备一笔交易,然后发送给 endorsers 来获得一个交易的背书
从一个客户端接收到 <SUBMIT, tx, retryFlag> 消息之后,submitting peer 首先验证客户端的签名 clientSig,然后准备一笔交易。这包括了 submitting peer 通过唤醒交易中指向的链上编码的操作和本地持有的状态先暂时执行一笔交易 (txPayload)。
作为执行交易后的结果,submitting peer 计算出一个状态更新 (stateUpdate) 和 版本依赖 (verDep),在数据库语言中也被称为MVCC+postimage info。
回想到状态有键值对组成。所有的键值对条目是版本化的,也就是,每一个条目都包含有序的版本信息,每一次键的值更新的时候,对应的版本信息都会增加。解释交易的 peer 记录所有被链上编码访问的键值对,要么是读要么是写,但是 peer 现在还不会更新它的状态,更具体的是:
verDep是一个元组verDep = (readset, writeset)。在 submitting peer 执行一笔交易前给定状态s:对于每一个被交易读取的键
k,(k, s(k).version)被加入readset。对于每一个被交易修改的键
k,(k, s(k).version)被加入writeset。
对于每一个被交易修改新值为
v'的键k,(k, v')被加入stateUpdate。或者,v'可以是新值相对于原先的值 (s(k).value) 的增量。
一个具体的实现可能会将 verDep.writeset 和 stateUpdate 集成到一个简单的数据结构中。
随后,tran-proposal := (spID, chaincodeID, txContentBlob, stateUpdate, verDep),其中,txContentBlob 是链上编码/交易的具体信息。意图是让 txContentBlob 作为 tx 的代表来使用 (例如,txContentBlob = tx.txPayload),更多细节将会在第六章给出。
tran-proposal 的加密哈希被所有的节点用来唯一标识交易 (tid),其中 tid = HASH(tran-proposal)。
随后 submitting peer 发送交易 (如 tran-proposal) 给链上编码所关心的 endorsers。根据链上编码中背书策略的解释和 peers 的可用性, Endorsing peers 被选择。例如,给定 chaincodeID 的交易被发送给所有的 endorsers,其中,会有一些 endorsers 离线,有一些拒绝和选择不为该交易背书。submitting peer 尝试同时满足背书策略和 endorsers 的可用性。
Submitting peer spID 使用以下消息发送交易给一个 endorsing peer epID:
<PROPOSE, tx, tran-proposal>
可能的优化: 一个具体的实现可以优化在 tx.chaincodeID 与 tran-proposal.chaincodeID 中重复出现的 chaincodeID,还有在 tx.txPayload 与 tran-proposal.txContentBlob 中重复出现的 txPayload。
最后,submitting peer 存储 tran-proposal 和 tid 于内存中,然后等待来自 endorsing peer 的回复。
可选的设计 (Alternative design): 以上描述的是 submitting peer 与 endorsers 点对点的直接交流通信。这也可以是一个被共识服务执行的函数操作;在这种情况下,需要决定 fabric 是必须遵从原子性广播来保证传输消息还是使用简单的点对点通信。在使用共识服务传输该消息的情况下,共识服务还要根据背书策略负责收集来自 endorsers 的背书并将其响应给 submitting peer。
TODO: 决定 submitting peer 与 endorsing peer 之间的通信是采用共识服务还是点对点。
2.3. 一个 endorser 接收并为一笔交易背书
当一笔交易通过 PROPOSE 消息并根据 tran-proposal.chaincodeID 对应的链上编码传递给一个 endorser 的时候,endorsing peer 执行以下步骤:
endorsers 验证
tx.clientSig和 确保tx.chaincodeID == tran-proposal.chaincodeID。endorsers 模拟这笔交易 (使用
tx.txPayload) 并验证状态更新和依赖信息是正确的。如果所有的都是有效的,endorsers 会对陈述(TRANSACTION-VALID, tid)进行数字签名产生epSig。然后 endorsing peer 发送<TRANSACTION-VALID, tid, epSig>消息给 submitting peer (tran-proposal.spID)。其它,在 endorsers 上模拟交易执行产生和
tran-proposal相同结果的失败情况下,我们区分为以下情况:a. 如果 endorsers 获取到与
tran-proposal.stateUpdate不同的状态更新结果,endorsers 对陈述<TRANSACTION-INVALID, tid, INCORRECT_STATE>进行签名,然后将签名过后的陈述发送给 submitting peer。b. 如果 endorsers 意识到比
tran-proposal.verDep更为先进的数据版本,它会对陈述<TRANSACTION-INVALID, tid, STALE_VERSION>签名,然后发送签名过后的陈述给 submitting peer。c. 如果由于任何其他原因 (内部的背书策略,交易中出现的错误),endorsers 不想为交易背书,它会对陈述
<TRANSACTION-INVALID, tid, REJECTED>进行签名,然后发送签名过后的消息给 submitting peer。
注意 endorsers 在这一步不会改变它的状态,更新不会被记录!
可选的设计 (Alternative design): endorsing peer 干脆忽略掉通知 submitting peer 无效的交易,不会发送显示的 TRANSACTION-INVALID 通知。
可选的设计 (Alternative design): endorsing peer 提交 TRANSACTION-VALID/TRANSACTION-INVALID 消息给共识服务来传送给 submitting peer。
TODO: 决定使用以上哪种设计。
2.4. submitting peer 收集交易的背书,并通过共识服务广播
submitting peer 等待直至它收集到足够的消息和签名 (对于<TRANSACTION-VALID, tid>),如此,submitting peer 便可以得出结论:交易提案被成功背书 (可能包括来自自己的签名),这些依赖于具体的链上编码背书策略 (第三章)。如果满足背书策略,交易就是背书过的 (endorsed);注意交易还没有被提交 (committed)。使得交易被背书成功的签名的集合被称为背书 (endorsement),peer 以 endorsement 来存储它们。
对于一笔交易,如果 submitting peer 没有成功收集到足够的消息和签名来证明该交易被成功背书,它会丢弃该笔交易并且通知客户端。如果 retryFlag 被设置,那么 submitting peer 也许 (根据自身策略) 会从 step 2 重试提交过程。
对于一笔成功背书的交易,我们现在开始 fabric 共识过程,submitting peer 使用 broadcast(blob) 来唤醒共识服务,其中,blob = (tran-proposal, endorsement)。
2.5. 共识服务传输一笔交易给 peers
当事件 deliver(seqno, prevhash, blob) 发生并且一个 peer 已经应用了所有比 seqno 更低的 blob中的状态更新的时候,peer 做以下事情:
根据
blob.tran-proposal.chaincodeID指向的链上编码来检查blob.endorsement是否是有效的。(这步可以不用等比seqno小的状态更新被成功执行。)与此同时,它验证依赖 (
blob.tran-proposal.verDep) 没有被违反。
根据状态更新选择的持续特性 (consistency property) 或者孤立保证 (isolation guarantee),依赖的验证可以以不同的方式来实现。例如,通过要求 readset 和 writeset 中每一个键相应的版本号与本地状态数据库中对应键的版本号相同来实现 可串行化 (serializability),拒绝不满足该要求的交易。另外一个例子,当 writeset 中的所有键在本地数据库中的版本号与在 writeset 中的版本号相同时,可以提供快照隔离 (snapshot isolation)。数据库文献包括更多的隔离保证。
TODO: 决定是采用可串行化还是允许链上编码定义具体的隔离级别。
如果所有的检查都通过,交易会被认为是有效的或者committed。这就意味着 peer 将该交易追加到总账中并且随后应用
blob.tran-proposal.stateUpdate到本地持有的区块链状态上。只有有效的交易才能改变状态。如果有任何一步检查失败,交易会被视为是无效的,peer 会丢弃该交易。值得注意的是,无效的交易是不会被 commit 的,不会改变状态,并且不会被记录。
另外,submitting peer 通知客户端丢弃的交易。如果 retryFlag 被设置,那么 submitting peer 也许 (根据自身策略) 会从 step 2 重试提交过程。
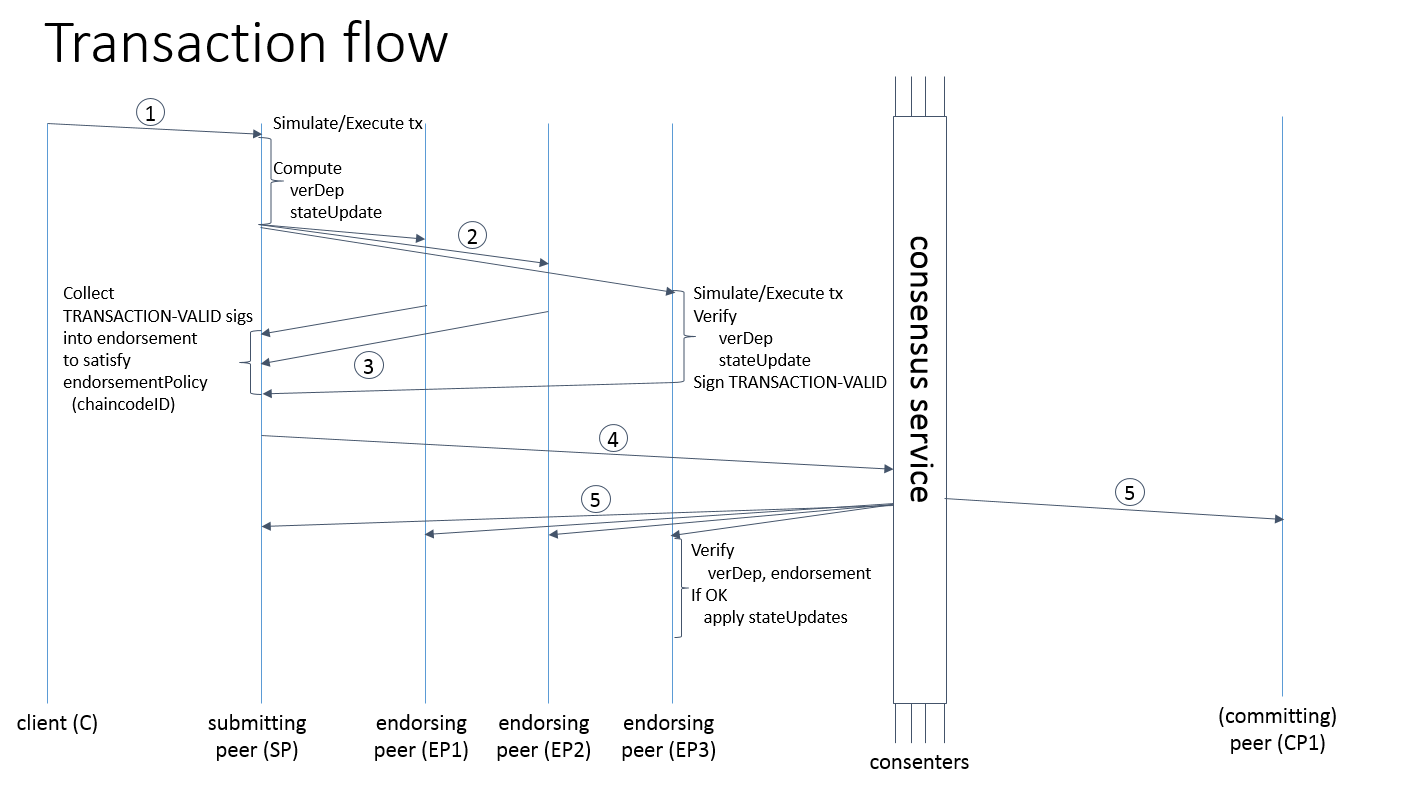
图 1. 交易的流程插图 (通常情况下)
3. 背书策略 (Endorsement policies)
3.1. 背书策略规范
一种背书策略,是一个关于背书一笔交易所需的条件。背书策略被安装具体链上编码的部署交易所指定。一笔交易只有根据背书策略被认可才能被声称为是有效的。对于链上编码的一笔唤醒交易首先要获取满足链上编码指定的背书策略的背书承诺 (endorsement) ,否则该笔交易不会被提交。这些会由 submitting peer 与 endorsing peer 之间的交互产生。
正式地来讲,背书策略是对交易、背书承诺、潜在的将来状态被评估为 TRUE 或者 FALSE 的一种预测。对于部署交易来说,根据系统的策略 (例如,来自系统级链上编码)来获取背书承诺。
正式地,一种背书策略是指向特定变量的预测。它可能会指向:
与链上编码 (存在于链上编码的 metadata) 相关联的键或者实体身份,例如,endorser 的集合;
链上编码进一步的 metada (further metadata of the chaincode);
交易本身的元素;
潜在的更多。
背书策略的预测评估必须是可决定性的。背书策略不应该很复杂,并且不能是 "mini chaincode"。背书策略所用的语言要被限制,并且被强制为是可决定的。
上述提到的,顺序越高,表现力和复杂性就越高,也就是,支持仅指向键和实体身份的策略是相对简单的。
TODO: 决定背书策略的参数。
预测可能会包含逻辑的表达式,并且可以被评估为 TRUE 或者 FALSE。典型地,对于链上编码,该条件将会在交易唤醒上使用由 endorsing peers 发行的数字签名。
假设链上编码定义了 endorser 集合 E = {Alice, Bob, Charlie, Dave, Eve, Frank, George}。一些可能的策略示例:
一个来自集合 E 所有成员的有效签名。
一个来自集合 E 任何一个成员的有效签名。
来自根据条件
(Alice OR Bob) AND (any two of: Charlie, Dave, Eve, Frank, George)成立的 endorsing peers 的有效签名。来自7个 endorsers 中的任何5个 endorsers 的有效签名。(更通用的,对于拥有 n>3f 个 endorser 的链上编码,n 个 endorser 中任意 2f+1个节点的有效签名或者一组大于(n+f)/2个节点的有效签名)。
假设每一个 endorser 都被赋有股份或者权重,就像
{Alice=49, Bob=15, Charlie=15, Dave=10, Eve=7, Frank=3, George=1},总股份为100:策略需要来自超过一半股份的 endorser 的有效签名 (例如,一组 stake 结合在一起大于50的 endorser),如{Alice, X},其中X是不同于George的所有其它的 endorser,或者{除 Alice 之外的所有其它 endorser}等等。上一个例子中的股权分配是静态的 (在链上编码的 metadata 中硬编码的),还可以是动态调整的 (例如,依赖于链上编码的状态,可以在交易执行后被修改)。
这些策略的用处依赖于应用程序自身,依赖于解决方案针对 endorser 的故障或者不正当行为所期望的弹性。
3.2. 实现
典型地,背书策略会根据所需的来自 endorser 的签名来制定。链上编码的 metadata 必须包含相应的验证签名的 keys。
一种背书策略通常由一个签名的集合组成。它能被每一个可以访问链上编码的 metadata (包含验证 keys) 的 peer 和 consenter 在本地评估,如此,节点既不需要和其它节点产生交互,也不需要访问状态来验证一个背书承诺。
指向链上编码其它元数据的背书承诺也可以以同样的方式来评估。
TODO: 正式确认背书策略,并设计一种实现。
4. 区块链数据结构
区块链由3种数据结构组成:a) 原始总账 (raw ledger),b) 区块链状态 (blockchain state) 和 c) 验证总账 (validated ledger)。区块链状态和验证总账被用来维持效率 - 它们可以从原始总账处产生。
原始总账 (RL)。 原始总账由共识服务向 peer 输出的所有数据组成。它是
deliver(seqno, prevhash, blob)事件组成的一个序列,根据prevhash形成了一条哈希链。原始总账包含了有效和无效的交易信息,提供了一个可确认的包含成功的以及不成功的状态改变和状态改变尝试的历史,发生于系统的操作过程中。原始总账允许 peers 重放所有的历史交易和重建区块链状态。它也向 submitting peer 提供了无效 (uncommitted) 交易相关信息,针对这些信息,submitting peer 可以执行2.5节描述的操作。
区块链状态。 peer 以 KVS 的形式来维护区块链状态。通过过滤掉原始总账中无效的交易 (于2.5节中描述) 来产生区块链状态,并且通过对于
stateUpdate中每一个(k, v)对执行put(k, v)操作来应用有效的交易到状态上,或者是应用相较于前一个状态的状态增量。通过共识服务的保证,所有正确的 peer 都会接收到相同的
deliver(seqno, prevhash, blob)事件序。正如背书策略与状态更新的版本依赖的评估是确定性的,所有正确的 peer 会就包含在blob中的交易是否有效达成一致。因此,所有 peer 会以相同的方式提交和应用相同的交易序列来更新区块链状态。验证总账 (VL)。 为了维护仅包含有效并且提交的交易信息的总账,peers 在区块链状态和原始总账的基础上维护验证总账。这是一条过滤掉原始总账中无效交易过后形成的哈希链。
4.1. Batch 与 区块信息
取而代之输出单个的交易信息,共识服务可能会输出 blob 组成的 batches。在这种情况下,对于每一个 batch,共识服务必须强制和输出一个确定性顺序的 blobs。根据具体的共识服务实现,每一个 batch 里的 blob 数量是动态的。
对 batch 进行共识不会影响原始总账的构建,原始总账将仍旧会是一条 blobs 的哈希链,但是与单个 blob 共识不同的是,原始总账将会变成是 batches 的哈希链。
使用 batch,验证总账的构建按下列方式产生。由于原始总账中的 batches 内可能会包含无效的交易 (无效的背书策略或者无效的状态更新版本依赖),这样的交易在被提交到一个区块里之前会被 peer 过滤掉。每一个 peer 自身做这些操作。一个区块被定义为不含无效交易的共识 batch。这样的区块的大小本质上是动态的,而且有可能是空的。下图描述了区块的构建
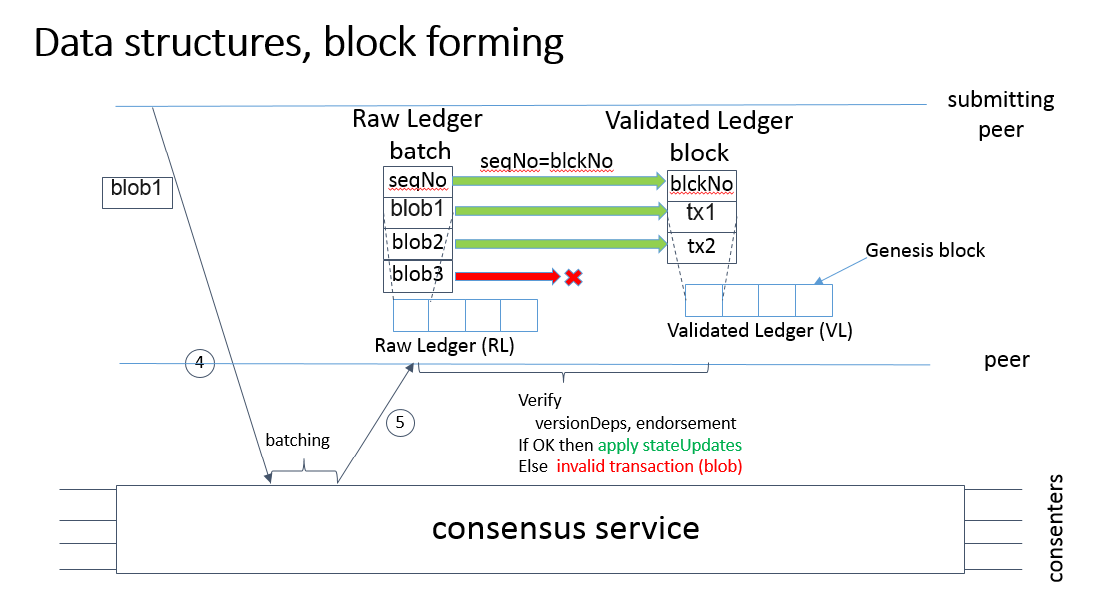
图 2. 区块的构建过程
4.2. 链接区块
共识服务输出的原始总账的 batches 形成一条哈希链,在 1.3.3 节中描述。
验证总账的区块被每一个节点链接成一条哈希链。来自 batch 中有效并且提交过的交易形成一个区块,所有区块被链接形成一条哈希链。
更具体地,验证总账中每一个有效的区块包含:
前一个区块的哈希值。
区块号。
自从上一个区块被计算后,一个有序的被 peer 提交的交易列表 (例如,相应 batch 中有效的交易列表)。
该区块从某个原始总账中的 batch 获得,该 batch 的哈希值。
以上所有的信息被关联起来,然后 peer 计算其哈希值,产生验证总账中区块的哈希值。
5. 状态转移与检查点
通常情况下,在正常的操作过程中,一个 peer 从共识服务处接收一系列的 deliver() 事件 (包含交易的 batches),追加这些 batches 到它的原始总账中,更新区块链状态,生成相应的验证总账。
然而,由于网络分割或者是节点的临时不可用,一个节点处的原始总账可能会丢失多个 batches。这种情况下,为了赶上网络中其它节点,该节点必须从其它节点处 传输状态 (transfer state)。 这一章描述了实现状态转移的方法。
5.1. 原始总账状态转移 (batch 转移)
为了说明基本的 状态转移 是如何工作的,我们假设节点 p 本地持有的原始总账中最后一个 batch 的序号为 25 (例如,最后一个接收到的 deliver() 事件中的 seqno 等于 25)。在某个时间点,节点 p 从共识服务处接收到 deliver(seqno=54, hash53, blob) 事件。
在这个时刻,节点 p 意识到它本地的原始总账丢失了序号为 26-53 的 batches。为了获得丢失的 batches,p 诉诸于点对点通信来与其它节点交流。它要求其它节点返回它丢失的 batches。当它状态转移的过程中,P 可以继续监听来自共识服务的新 batches。
注意 p 不必信任任何在状态转移过程中获得丢失 batches 时使用的节点。 因为 p 有 batch 53 的哈希值 (称为 hash53),既然是 p 从共识服务处直接获得的哈希值,所该哈希值是可信任的。一旦所有丢失的 batches 到达节点 p 的时候,p 就能够验证丢失的 batches 的完整性。该验证检查它们是否构成了合适的哈希链。
一旦 p 获得了所有丢失的 batches 并且验证了丢失的 batches 26-53,它就能对 batches 26-54 继续 2.5 章提到的步骤。然后 p 就可以继续构建区块链状态和验证总账。
注意一旦 p 接收到更低序号的 batches 时,它就可以开始探测性地重建区块链状态和验证总账,即使它仍然缺失一些更高序号的 batches。然而,在外化状态和提交区块到验证总账之前,p 必须完成所有丢失的 batches 的传输 (在我们的例子中,一直到 batch 53,全部包括) 和单独传输的 batches 的处理。
5.2. 检查点
原始总账包含无效的交易,无效的交易没有必要被永久地存储。然而,当 peers 一旦建立了相应的验证总账中的区块后,peers 也不能简单地丢弃原始总账中的 batches,并且因此对原始总账进行剪枝。在剪枝的情况下,如果一个新的节点加入了网络,其它节点既无法向该新节点传输丢失的 batches,也不能使该新节点信服来自它们验证总账中的区块的有效性。
为了加快原始总账的剪枝,这篇文献描述了一种 检查点 (checkpointing) 机制。这种机制使跨节点网络的验证总账的区块的有效性得到认可,并且允许 checkpointed 验证总账来代替被丢弃的原始总账。反过来,该机制也降低了存储空间,因为没有必要存储无效的交易。对于新节点来说,它也降低了重建状态的工作量,因为它们没有必要再从原始总账中证实单个交易的有效性,可以简单地重放包含在验证总账中的状态更新。
注意检查点加快了原始总账的剪枝,但它仅仅是性能优化上的需求。对于架构设计的正确性来说,检查点不是必须的。
5.2.1. 检查点协议
检查点会周期性地每 CHK 个区块被 peers 执行,其中 CHK 是一个可配置的参数。为了初始化一个检查点,peers 会像其它 peers 广播消息 <CHECKPOINT, blocknohash, blockno, peerSig>,其中 blockno 是当前的区块序列号,blocknohash 是它相应的区块哈希值,peerSig 是节点对指向验证总账的 <CHECKPOINT, blocknohash, blockno> 的签名。
一个节点收集 CHECKPOINT 消息,直至它获取了足够多的正确签过名的具有相同 blockno 与 blocknohash 的消息来创建一个 有效的检查点 (valid checkpoint)。
对于 blockno 与 blocknohash 一旦建立了有效的检查点,一个节点:
如果
blockno > latestValidCheckpoint.blockno,那么一个节点赋值latestValidCheckpoint = (blocknohash, blockno),存储构成有效检查点的 peers 签名集合到
latestValidCheckpointProof。(可选地) 剪枝原始总账到 batch number
blockno(闭区间)。
5.2.2. 有效检查点
检查点协议引出了一下问题:一个节点什么时候剪枝它的原始总账? 多少个 CHECKPOINT 消息才算足够多的?。这些是被一个检查点有效策略所定义的,至少有两种可能的方案,也可能结合起来:
本地 (节点具体化) 检查点有效策略(LCVP)。 一个给定节点上的本地策略也许具体了节点的集合 p_s ,节点 p 信任 p_s 并且来自 p_s 的
CHECKPOINT消息对于建立一个有效的检查点是足够有效的。例如,节点 Alice 处的 LCVP 定义了 Alice 需要从 Bob 或者从 Charlie 与 Dave 节点接收CHECKPOINT消息。全局检查点有效策略 (GCVP)。 一个检查点有效策略也许会被全局地具体定义。这与 LCVP 是相似的,除了,它是在全局系统粒度上规定的,而不是节点的粒度上。比如,GCVP 也许是这样的:
每个节点信任一个检查点,如果该检查点被 7 个不同的节点确认。
在每个 consenter 同时是 peer 的部署中,其中,可能最多有 f 个 consenter 是拜占庭错误的,那么每个节点可能会信任一个被 f+1 个不同 consenter 确认的 CHECKPOINT 消息。
5.2.3. 验证总账状态转移 (区块转移)
除去使原始总账的剪枝加快之外,检查点能够通过验证总账区块转移来实现状态转移。在状态转移过程中,验证总账能够部分代替原始总账。
概念上,区块转移的工作机制与 batch 转移是相似的。回想一个节点 p 丢失了 batches 26-53 的例子中,假设从一个已经在区块 50 建立了有效检查点的节点 q 进行状态转移,需要以下两步:
首先,p 试图从节点 q 处获取验证总账直到区块 50,为此,q 发送它本地的
(latestValidCheckpoint, latestValidCheckpointProof)给节点 p。如果latestValidCheckpointProof也满足在节点 p 处的检查点有效策略,那么区块 26 到 50 的转移是可能的。否则,节点 q 不能使 p 信服它的检查点是有效的。然后节点 P 可能选择原始总账的 batches 转移来继续推进。如果区块 26-50 转移成功,节点 p 仍然需要通过获取验证总账的 51-53 区块或者原始总账的 51-53 batches 来完成状态的转移。为此,p 可以简单地使用原始总账 batches 转移协议从节点 q 或者其它节点处获得所需的 batches。注意验证总账的区块中包含相应的原始总账的 batches 的哈希值。因此原始总账的 batch 转移能够完成,即使在节点 p 处的原始总账中并没有 batch 50,因为 batch 50 的哈希值被包含在了区块 50 中。
附录
1. 可串行化 (serializability) 与快照隔离 (snapshot isolation) 的理解
参照 https://blogs.msdn.microsoft.com/craigfr/2007/05/16/serializable-vs-snapshot-isolation-level/
该博客提到了一个形象的例子:假设我们现在有白球和黑球混合的袋子,白球和黑球各 2 个。假定我们想运行两笔交易,第一笔交易将袋子中所有白球转换为黑球,第二笔交易将袋子中所有黑球转换为白球。如果我们在串行化隔离的情况下运行这两笔交易,我们必须一次运行一笔交易,第一笔交易过后,袋子中只剩下黑球。第二笔交易过后,袋子中只剩下白球。因此,只有两种可能的情况:a)袋子中只有黑球;b)袋子中只有白球。
如果我们在快照隔离的情形下运行这两笔交易,除了串行化隔离情形下两种可能情况之外,还有第三种可能的情况。每一笔交易能在彼此改变袋子里球的颜色之前,取得一份袋子的快照。第一笔交易将袋子中所有白球转换为黑球,与此同时,第二笔交易将袋子中所有黑球转换为白球 (仅仅是袋子快照中的两个黑球,而不是第一笔交易过后的四个黑球)。到头来,我们仍然拥有两个白球和两个黑球的袋子,而实际上,我们已经恰好转换了每一个球的颜色。
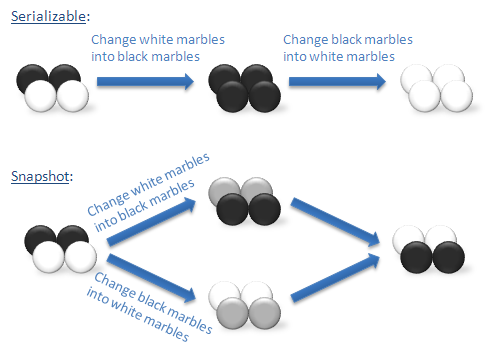
类比上面提到的例子,我们来回顾一下节点在接收到来自共识服务输出的消息后,对 blob.tran-proposal.verDep 的验证。
假设本地状态数据库中有四个键值对,分别为 (A, ["black", 0])、(B, ["black", 0])、(C, ["white", 0])、(D, ["white", 0])。 链上编码中有一个函数为 switch_marbles_black_white(),该函数的作用是遍历本地状态数据库,若发现黑球,则将其转化为白球;另一个函数为 switch_marbles_white_black(),该函数的作用是遍历本地状态数据库,若发现白球,则将其转换为黑球。
当有一笔唤醒该链上编码上的 switch_marbles_black_white() 函数的交易出现在区块链网络中时,随后,第二笔唤醒该链上编码上的 switch_marbles_white_black() 函数的交易出现在区块链网络中。第一笔交易的 readset 为 [(A, 0), (B, 0), (C, 0), (D, 0)],writeset 为 [(A, 0), (B, 0)];第二笔交易的 readset 为 [(A, 0), (B, 0), (C, 0), (D, 0)],writeset 为 [(C, 0), (D, 0)]。
当节点 p 接收到来自共识服务输出的这两笔交易对应的消息时,假设共识服务对第一笔和第二笔交易达成的顺序是第一笔交易->第二笔交易。p 需要对 blob.tran-proposal.verDep 进行验证。
在串行化隔离的情形下,第一笔交易执行完成后,此时本地状态数据库变为 (A, ["white", 1])、(B, ["white", 1])、(C, ["white", 0])、(D, ["white", 0]);此时第二笔交易执行,由于它的 readset 中 [(A, 0), (B, 0)] 与本地状态数据库中相应键的版本号不符,因此节点 p 拒绝执行该交易,所以最终结果为本地状态数据库中全为白球。
在快照隔离的情形下,第一笔交易执行完成后,此时本地状态数据库变为 (A, ["white", 1])、(B, ["white", 1])、(C, ["white", 0])、(D, ["white", 0]);此时第二笔交易执行,由于它的 writeset 中所有的键与本地状态数据中相应键的版本号相同,因此节点 p 验证该笔交易有效,然后执行该交易,执行完成后本地状态数据库变为 (A, ["white", 1])、(B, ["white", 1])、(C, ["black", 1])、(D, ["black", 1])。
2. 区块链系统并发的讨论
参照 https://github.com/hyperledger-archives/fabric/issues/1631#issue-157231212
原则上,目前我们有两种方法来处理并发。
a)版本依赖 (verDep):该方法一般在数据库中使用,当对数据库中一个对象并发的改变是附有条件的,就是该对象不能同时改变。这提供了可用性级别,在分布式计算中被称为,阻塞自由 (obstruction freedom)。用数据库的说法,我们需要具体化隔离保证,也许针对每一个链上编码都有不同的隔离保证,而不是全局性的。
b)通过 leader 排序:这种方法经常被分布式系统使用,会有一个 leader endorser 来给并发的请求排序,解决并发。这种方法被 Sieve 协议采用,该协议是目前 fabric 原型共识协议 (http://arxiv.org/abs/1603.07351)。
两种方法都有各自的优缺点:
"verDep" 优点:
- 比 "leader" 更加容易编写 HL fabric 代码。
- 如果没有对同一个对象的并发修改,允许大量链上编码并行化执行。
- 针对一些数据模型例如比特币的 UTXO 是合适的,在 UTXO 模型里不应该对同一对象有并发的修改 (会形成双花的可能)。
"verDep" 缺点:
- 阻塞可用性 (obstruction-free liveness) : 在没有并发修改同一对象的情况下才能提交。
- 对于习惯于中心化-非并发 (centralized-non-concurrent) 的程序猿来说,编写链上编码将会更困难。
"leader" 优点:
- 等待-释放可用性 (wait-free liveness) :不管是否并发,交易将会被 leader endorser 排序。
- 更容易编写链上编码:一个经典的计数器就可以。
"leader" 缺点:
- 编写 HL fabric 代码更加困难:需要在节点级别实现 leader 选举算法,可能在每一个链上编码。
- 限制了链上编码并行执行
最后,哪一种方法更加好,将会依赖于数据的模型以及允许并发数据修改的粒度级别。
一些拥有两种方法优点的想法:
让 "verDep" 处理计数器的实现。计数器能够模拟真实世界中的投票,选民 (voters) 对于一个候选增加一个计数,来标识他们的投票,其它的人随后记录投票数量。
结合两种方法:原则上,在一个系统中集成两种方法是可能的 (w.sharding),但是显然提高了系统的复杂度。